
I wanted to talk a little about the architecture I designed recently for a Dynamics CRM + Portal + Integration project. In the initial stages of the project a number of options were considered for a Portal (or group of portals) which would support staff, students and other users which would integrate with Dynamics CRM and other applications in the application estate. One of the challenges I could see coming up in the architecture was the level of coupling between the Portal and Dynamics CRM. Ive seen this a few times where an architecture has been designed where the portal is directly querying CRM Integration and has the CRM SDK embedded in it which is an obviously highly coupled integration between the two. What I think is a far bigger challenge however is the fact that CRM Online is a SaaS application and you have very little control over the tuning and performance of CRM.
Lets imagine you have 1000 CRM user licenses for staff and back office users. A customer experience platform is going to be your core system of record for customers which is why industries like mortgages and others may wish to pay attention here. You want to build systems of engagement to drive a positive customer experience and creating a Portal which can communicate with CRM is a very likely scenario. When you have bought your 1000 licenses from Microsoft you are going to be given the infrastructure to support the load from 1000 users. The problem however is your CRM portal being tightly coupled to CRM may introduce another amount of users on top of the 1000 back office users. Well whats going to happen when you have 50,000 students or a thousands/millions of customers starting to use your portal. You now have a problem that CRM may become a bottle neck to performance but because its SaaS you have almost no options to scale up or out your system.
With this kind of architecture you have the choices to roll your own portal using .net and either Web API or CRM SDK integration directly to CRM. There are also options to use products like ADXStudio which can help you build a portal too. The main reason these options are very attractive is because they are probably the quickest to build and minimize the number of moving parts. From a productivity perspective they are very good.
An illustration of this architecture could look something like the below:
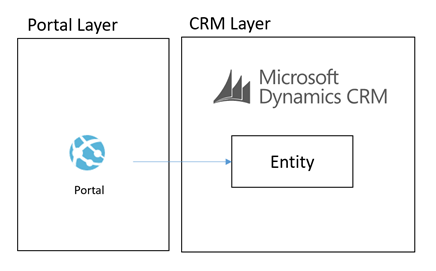
What we were proposing to do instead was to leverage some of the powerful features of Azure to allow us to build an architecture for a Portal which was integrated with CRM Online and other stuff which would scale to a much higher user base without having performance problems on CRM. Noting that problems in CRM could create a negative experience for Portal Users but also could significantly effect the performance of staff in the back office is CRM was running slow.
To achieve this we decided that using asynchronous approaches with CRM and hosting an intermediate data layer in Azure would allow us at a relatively low cost have a much faster and more scalable data layer to base the core architecture on. We would call this our cloud data layer and it would sit behind an API for consumers but be fed with data from CRM and other applications which were both on premise and in the cloud. From here the API was to expose this data to the various portals we may build.

The core idea was that the more we could minimize the use of RPC calls to any of our SaaS or On Premise applications the better we would be able to scale the portal we would build. Also at the same time the more resilient they would be to any of the applications going down.
Hopefully at this point you have an understanding of the aim and can visualise the high level architecture. I will next talk through some of the patterns in the implementation.
Simple Command from Portal
In this patter we have the scenario where the portal needs to send a simple command for something to happen. The below diagram will show how this works.
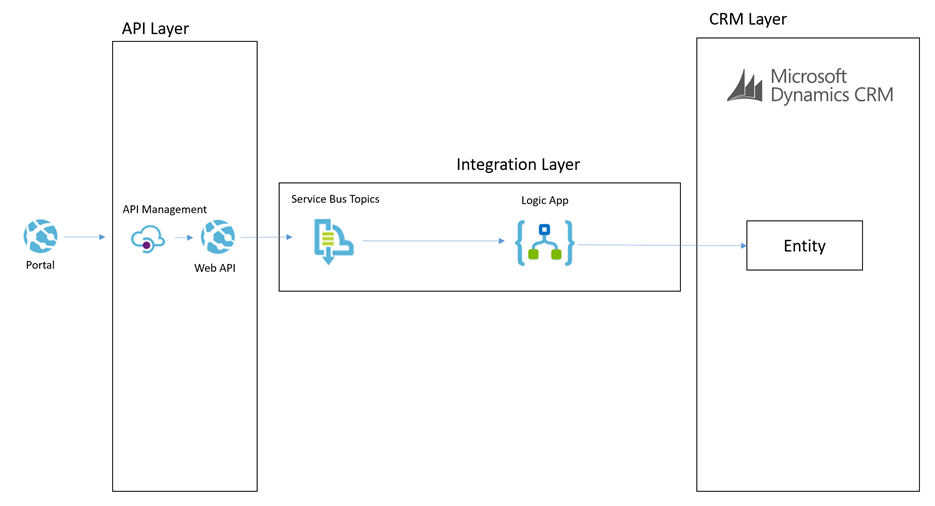
Lets imagine a scenario of a user in the portal adding a chat comment to a case.
The process for the simple command is:
- The portal will send a message to the API which will do some basic processing but then it will off load the message to a service bus topic
- The topic allows us to route the message to many places if we want to
- The main subscriber is a Logic App and it will use the CRM connectors to be able to interact with the appropriate entities to create the chat command as an annotation in CRM
This particular approach is pretty simple and the interaction with CRM is not overly complicated. This is a good candidate to use the Logic App to process this message.
Complex Command from Portal
In some cases the portal would publish a command which would require a more complex processing path. Lets imagine a scenario where the customer or student raised a case from the portal. In this scenario the processing could be:
- Portal calls the API to submit a case
- API drops a message onto a service bus topic
- BizTalk picks up the message and enriches with additional data from some on premise systems
- BizTalk then updates some on premise applications with some data
- BizTalk then creates the case in CRM
The below picture might illustrate this scenario

In this case we choose to use BizTalk rather than Logic Apps to process the message. I think as a general rule the more complex the processing requirements, the more I would tend to lean towards BizTalk than Logic Apps. BizTalks support for more complex orchestration, compensation approaches and advanced mapping just lends itself a little better in this case.
I think the great thing in the Microsoft stack is that you can choose from the following technologies to implement the above two patterns behind the scenes:
- Web Jobs
- Functions
- Logic Apps
- BizTalk
Each have their pro’s and con’s which make them suit different scenarios better but also it allows you to work in a skillset your most comfortable with.
Cloud Data Layer
Earlier in the article I mentioned that we have the cloud data layer as one of our architectural components. I guess in some ways this follows the CQRS pattern to some degree but we are not specifically implementing CQRS for the entire system. Data in the Cloud Data Layer is owned by some other application and we are simply choosing to copy some of it to the cloud so it is in a place that will allow us to build better applications. Exposing this data via an API means that we can leverage a data platform based on Cosmos DB (Document DB) and Azure Table Storage and Azure Blob Storage.
If you look at Cosmos DB and Azure Storage, they are all very easy to use and to get up and running with but the other big benefits is they offer high performance if used right. By comparison, we have little control over the performance of CRM online, but with Cosmos DB and Azure Storage we have lots of options over the way we index and store data to make it suit a high-performing application without all of the baggage CRM would bring with it. If you’re looking into different ways to store data as part of your data modelling then it’s important to consider these things as the amount of control you have over your data matters a lot. If you’re asking “what is data modelling?” then follow that link to find out more about it.
The main difference over how we use these data stored to make a combines data layer is:
- Cosmos DB is used for a small amount of meta data related to entities to aid complex searching
- Azure Table store is used to store related info for fast retrieval by good partitioning
- Azure Blob Storage is used for storing larger json objects
Some examples of how we may use this would be:
- In an azure table a students courses, modules, etc may be partitioned by the student id so it is fast to retrieve the information related to one student
- In Cosmos DB we may store info to make advanced searching efficient and easy. For example find all of the students who are on course 123
- In blob storage we may store objects like the details of a KB article which might be a big dataset. We may use Cosmos DB to search for KB articles by keywords and tags but then pull the detail from Blob Storage
CRM Event to Cloud Data Layer
Now that we understand that queries of data will not come directly from CRM but instead via an API which exposes an intermediate data layer hosted on Azure. The question is how is this data layer populated from CRM. We will use a couple of patterns to achieve this. The first of which is event based.
Imagine that in CRM each time an entity is updated/etc we can use the CRM plugin for Service Bus to publish that event externally. We can then subscribe to the queue and with the data from CRM we can look up additional entities if required and then we can transform and push this data some where. In our architecture we may choose to use a Logic App to collect the message. Lets imagine a case was updated. The Logic App may then use info from the case to look up related entity data such as a contact and other similar entities. It will build up a canonical message related to the event and then it can store it in the cloud data layer.
Lets imagine a specific example. We have a knowledge base article in CRM. It is updated by a user and the event fires. The Logic App will get the event and lookup the KB article. The Logic App will then update Cosmos DB to update the metadata of the article for searching by apps. The Logic App will then transform the various related entities to a canonical json format and save them to Blob storage. When the application searches for KB articles via the API it will be under the hood retrieving data from Cosmos DB. When it has chosen a KB article to display then it will retrieve the KB article details from blob storage.
The below picture shows how this pattern will work.
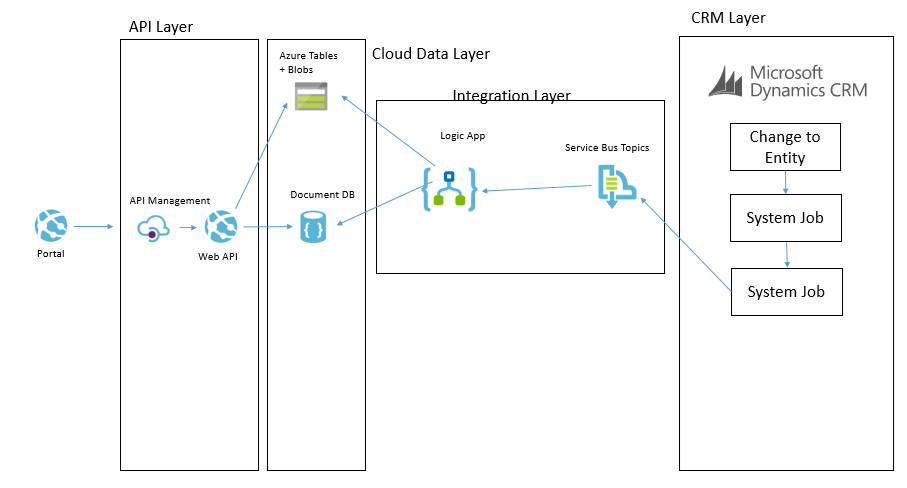
CRM Entity Sync to Cloud Data Layer
One of the other ways we can populate the cloud data layer from CRM is via a with a job that will copy data. There are a few different ways this can be done. The main way will involve executing a fetch xml query against CRM to retrieve all of the records from an entity or all of the records that have been changed recently. They will then be pushed over to the cloud data layer and stored in one of the data stores depending on which is used for that data type. It is likely there will be some form of transformation on the way too.
An example of where we may do this is if we had a list of reference data in CRM such as the nationalities of contacts. We may want to display this list in the portal but without querying CRM directly. In this case we could copy the list of entities from CRM to the cloud data layer on a weekly basis where we copy the whole table. There are other cases where we may copy data more frequently and we may use different data sources in the cloud data layer depending upon the data type and how we expect to use it.
The below example shows how we may use BizTalk to query some data from CRM and then we may send messages to table storage and Cosmos DB.
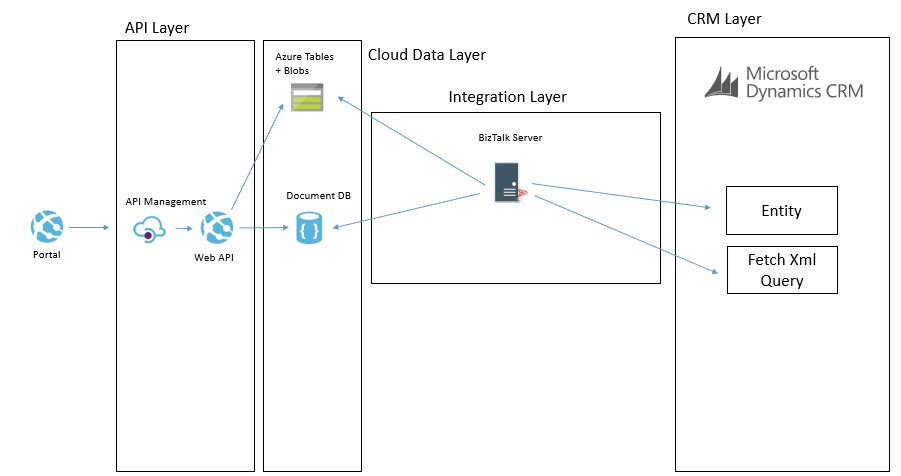
Another way we may solve this problem is using Data Factory in Azure. In Data Factory we can do a more traditional ETL style interface where we will copy data from CRM using the OData feeds and download it into the target data sources. The transformation and advanced features in Data Factory are a bit more limited but in the right case this can be done like in the below picture.
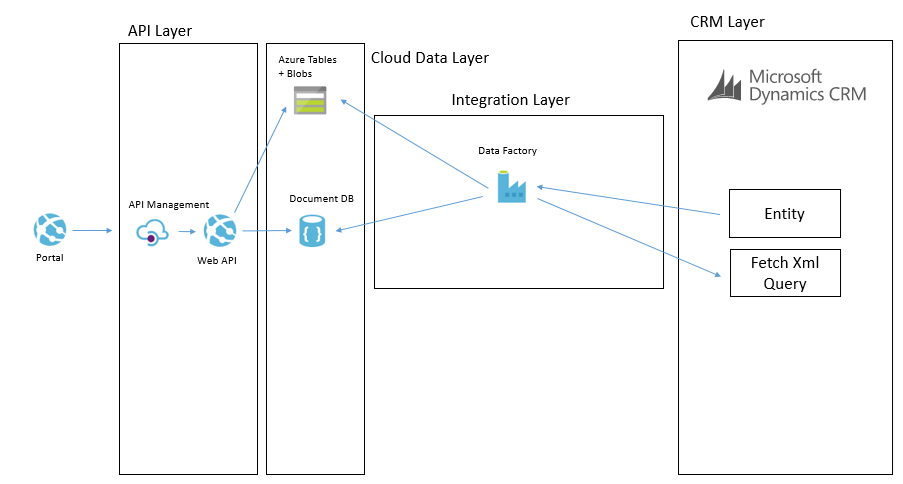
In these data synchronisation interfaces it will tend to be data that doesn’t change that often and data which you don’t need the real time event to update it which it will work the best with. While I have mentioned Data Factory and BizTalk as the options we used, you could also use SSIS, custom code and a web job or other options to implement it.
Summary
Hopefully the above approach gives you some ideas how you can build a high performing portal which integrated with CRM Online and potentially other applications but by using a slightly more complex architecture which introduces asynchronous processing in places and CQRS in others you can create a decoupling between the portal(s) you build and CRM and other back end systems. In this case it has allowed us to introduce a data layer in Azure which will scale and perform better than CRM will but also give us significant control over things rather than having a bottle neck on a black box outside of our control.
In addition to the performance benefits its also potentially possible for CRM to go completely off line without bringing down the portal and only having a minimal effect on functionality. While the cloud data layer could still have problems, firstly it is much simpler but it is also using services which can easily be geo-redundant so reducing your risks. An example here of one of the practical aspects of this is if CRM was off line for a few hours while a deployment is performed I would not expect the portal to be effected except for a delay in processing messages.
I hope this is useful for others and gives people a few ideas to think about when integrating with CRM.





{kind=link}
{kind=link}
{kind=link}
{kind=link}